RAGEN
Training Agents by Reinforcing Reasoning
LLM Agents + Multi-turn Reinforcement Learning
to train LLM reasoning agents in interactive, stochastic environments.
Announcing VAGEN for VLM Agents >
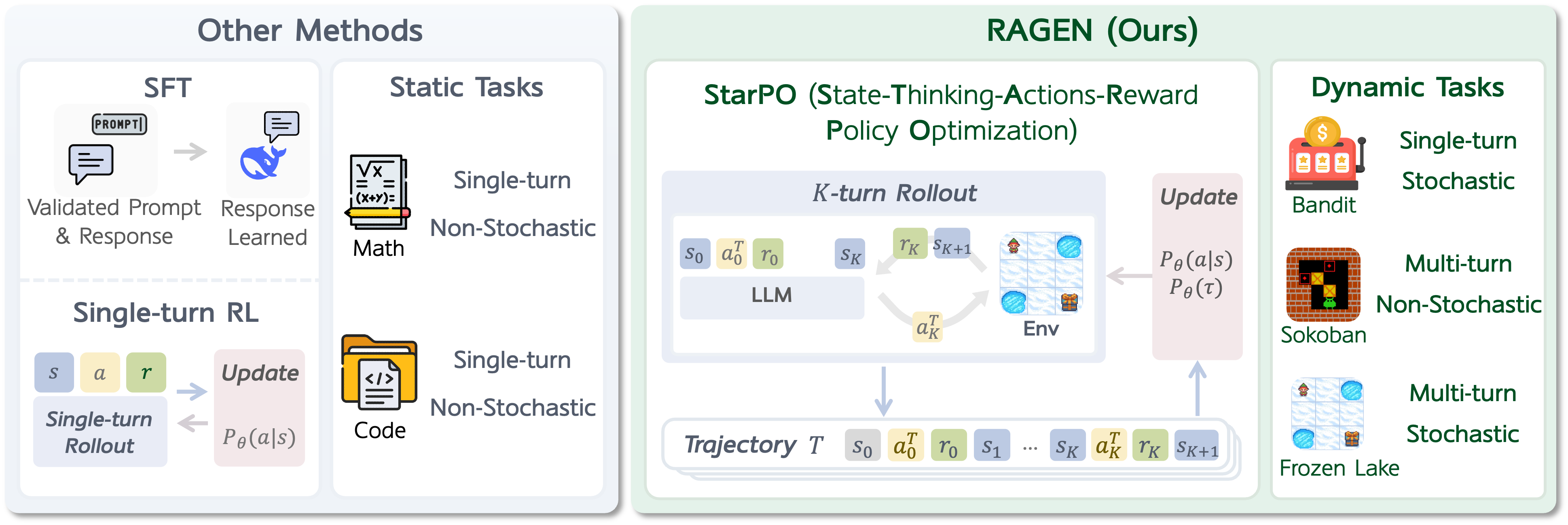
Comparison between RAGEN and existing LLM training methods.
StarPO (State-Thinking-Action-Reward Policy Optimization)
Initial State
Reasoning
Action
Reward
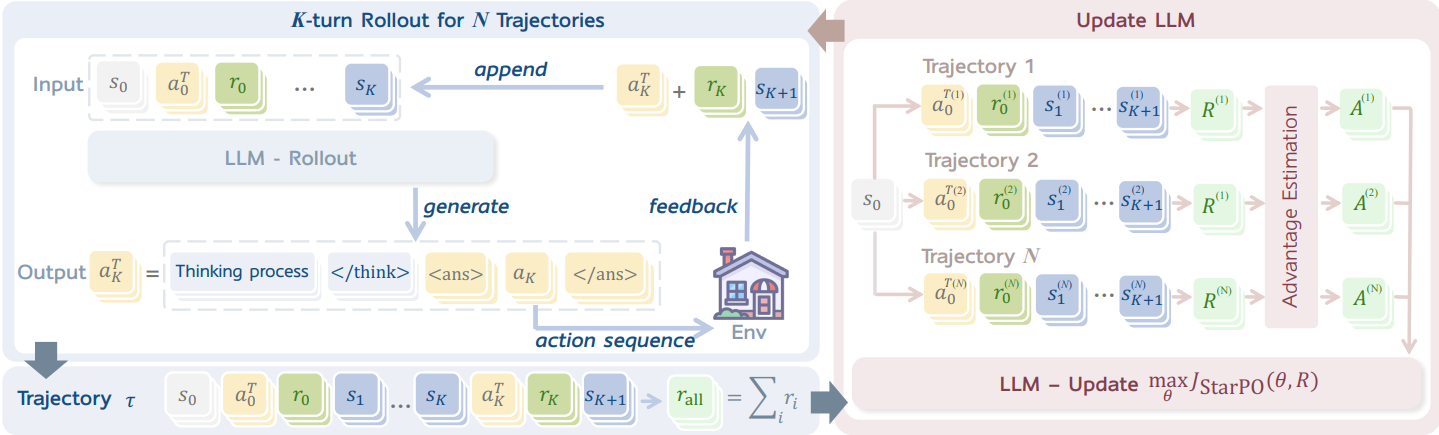
The StarPO (State-Thinking-Action-Reward Policy Optimization) framework with two interleaved stages: rollout stage and update stage.
MDP Formulation
We formulate agent-environment interactions as Markov Decision Processes (MDPs) where states and actions are token sequences, allowing LLMs to reason over environment dynamics.
At time \(t\), state \(s_t\) transitions to the next state through action \(a_t\) following a transition function \(P(s_{t+1} | s_t, a_t)\). The policy \(\pi(a_t | s_t)\) generates actions given the trajectory history. The objective is to maximize expected cumulative rewards \(\mathbb{E}_\pi[\sum_t \gamma^t r_t]\) across multiple interaction turns.
StarPO: Reinforcing Reasoning via Trajectory-Level Optimization
StarPO is a general RL framework for optimizing entire multi-turn interaction trajectories for LLM agents. The algorithm alternates between two phases:
Rollout Stage: Reasoning-Interaction Trajectories
Given an initial Sokoban puzzle state, the LLM generates multiple solving trajectories. At each step, the model receives the puzzle state and generates a reasoning-guided action to push boxes to goal positions:
<think>I need to push the box ($) to the goal (.) which is directly to the right.</think><ans> Right </ans> The environment receives the action and returns the next state with the box pushed to the goal.
#_@*#
#####
Box pushed to goal position. State updated.
Update Stage: Multi-turn Trajectory Optimization
After generating trajectories, we train LLMs to optimize expected rewards. Instead of step-by-step optimization, StarPO optimizes entire trajectories using importance sampling. This approach enables long-horizon reasoning while maintaining computational efficiency.
StarPO supports multiple optimization strategies:
PPO (Proximal Policy Optimization):
GRPO (Group Relative Policy Optimization):
Rollout and update stages interleave in StarPO, enabling both online and offline learning.
Findings
Finding 1: Single-turn RL may not be directly adapted to Multi-turn agent RL
Vanilla adaptations from single-turn methods like PPO and GRPO achieve early gains in agent settings but often collapse. A critic in PPO may delay instability, but would not prevent reasoning degradation, highlighting the need for specialized stabilization in agent settings.
Finding 2: Model collapse in agent RL is reflected as "Echo Trap" over training
We find that early-stage agent respond with diverse symbolic reasoning, but collapse into deterministic, repetitive templates after training. Models converge to fixed phrasing, indicating that RL may reinforce superficial patterns instead of general reasoning and forms an "Echo Trap" that hinders long-term generalization.
Finding 3: Collapse follows similar dynamics and can be anticipated by indicators
Reward standard deviation and entropy often fluctuate before performance degrades, while gradient norm spikes typically mark the point of irreversible collapse. These metrics provide early indicators and motivate the need for stabilization strategies.
Finding 4: Filtering low-variance trajectories improves stability and efficiency
Training on high-variance prompts delays or eliminates collapse in multi-turn RL. StarPO-S improves performance and reduces update steps by discarding low-information rollouts, especially under PPO. This aligns with active learning principles, where uncertain examples offer the most informative learning signals.
Finding 5: Task diversity, action budget, and rollout frequency affect data quality
Diverse task instances enable better policy contrast and generalization across environments. Moderate action budgets provide enough planning space and avoid the noise introduced by overly long sequences. Up-to-date rollouts ensure optimization targets remain aligned with current policy behavior.
Finding 6: Reasoning fails to emerge without meticulous reward design
RAGEN Trajectory Examples
Explore agent trajectories across different tasks. View state transitions, LLM-generated actions, and the decision-making process.
Loading trajectory data...
State

State description will appear here. This represents the environment's current state at the selected step.
LLM Response
Reasoning:
Let me think about the current state...