RAGEN-2
Reasoning Collapse in Agentic RL
ICML 2026 Oral
Even when entropy stays high, agents can quietly stop listening to inputs — producing fluent but input-agnostic boilerplate. We call this template collapse.
Method
A Two-Axis View of Reasoning Quality
where X = input prompt, Z = model output:
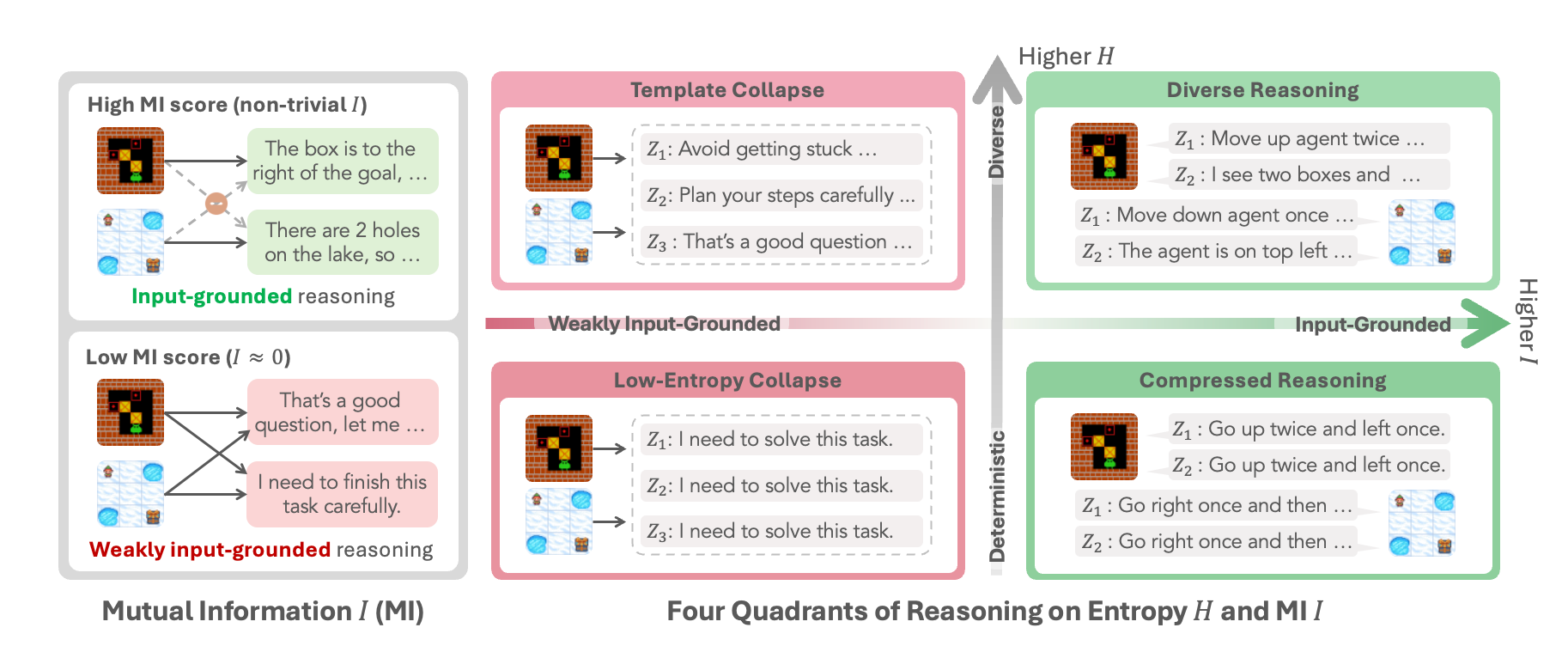
Figure 1. Template collapse (top-left): entropy looks healthy, but outputs are input-agnostic.
Detecting Template Collapse
Score every output against every input. In a healthy model, the diagonal dominates. Under collapse, all rows look the same.
| X1 | X2 | X3 | |
|---|---|---|---|
| Z1 | 0.9 | 0.1 | 0.2 |
| Z2 | 0.2 | 0.8 | 0.1 |
| Z3 | 0.1 | 0.2 | 0.9 |
| X1 | X2 | X3 | |
|---|---|---|---|
| Z1 | 0.5 | 0.5 | 0.4 |
| Z2 | 0.4 | 0.5 | 0.5 |
| Z3 | 0.5 | 0.4 | 0.5 |
Why Collapse Happens: Signal vs. Noise
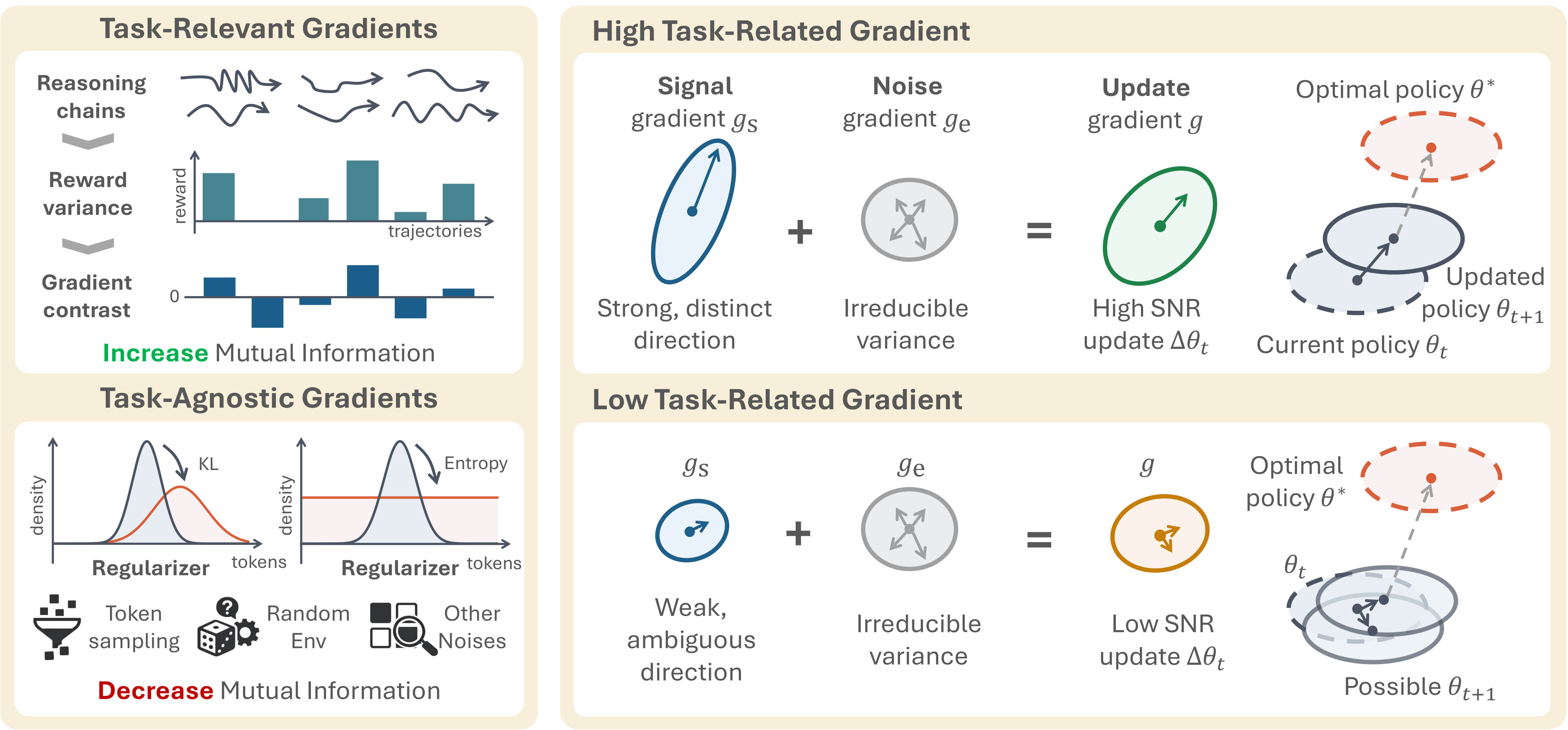
Low reward variance → noise dominates → outputs converge to a single template.
RAGEN-2: SNR-Adaptive Filtering
- Sample rollouts per prompt, compute reward variance.
- Keep top ρ fraction (high-signal prompts).
- Run PPO / GRPO on the retained subset.

Experiments
Click each question to expand the evidence.
MI declines before performance — entropy stays high
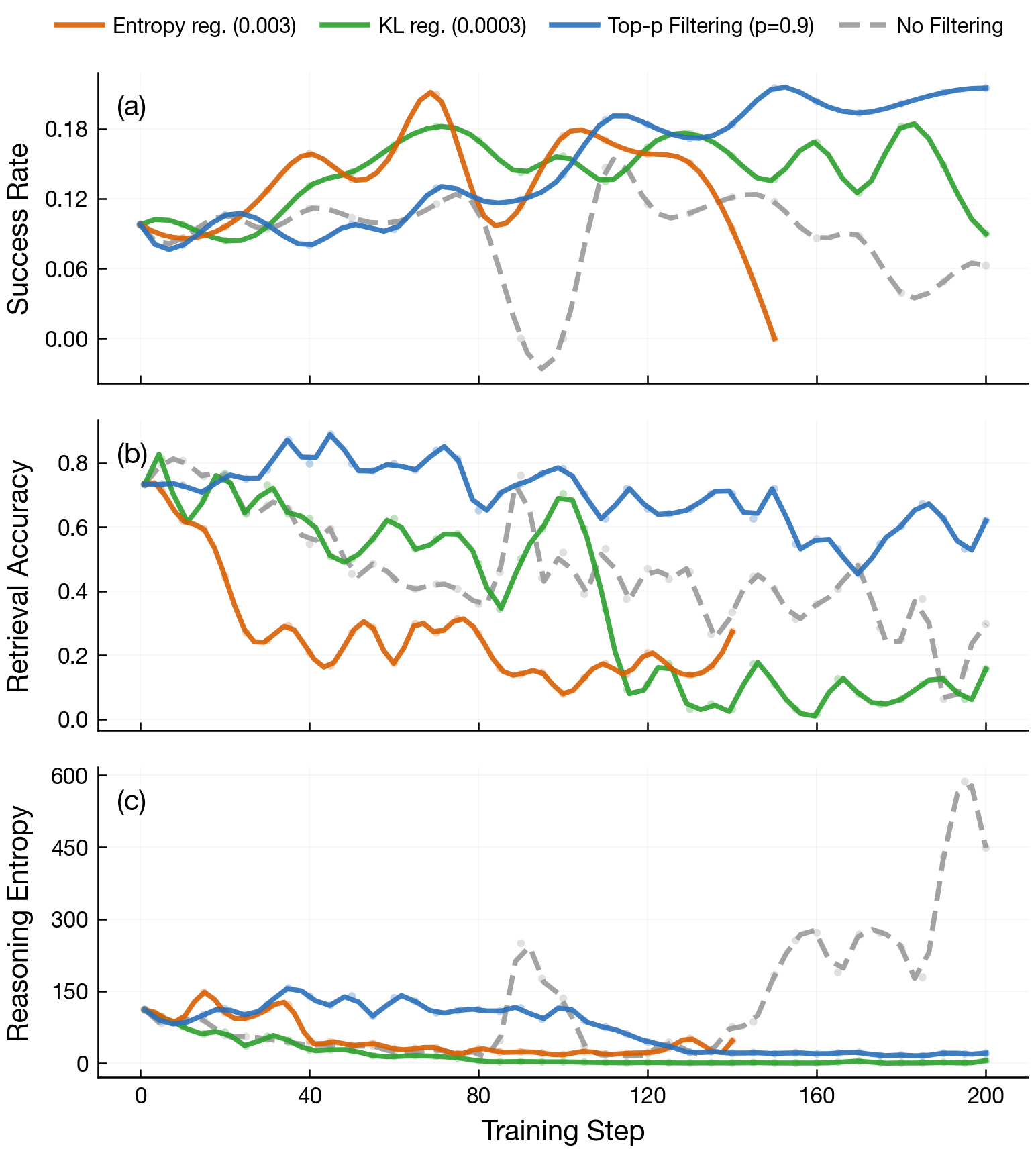
MI proxy declines before task performance degrades, while conditional entropy remains elevated — demonstrating that entropy alone is insufficient to detect template collapse.
Spearman correlation: MI vs Entropy as diagnostics
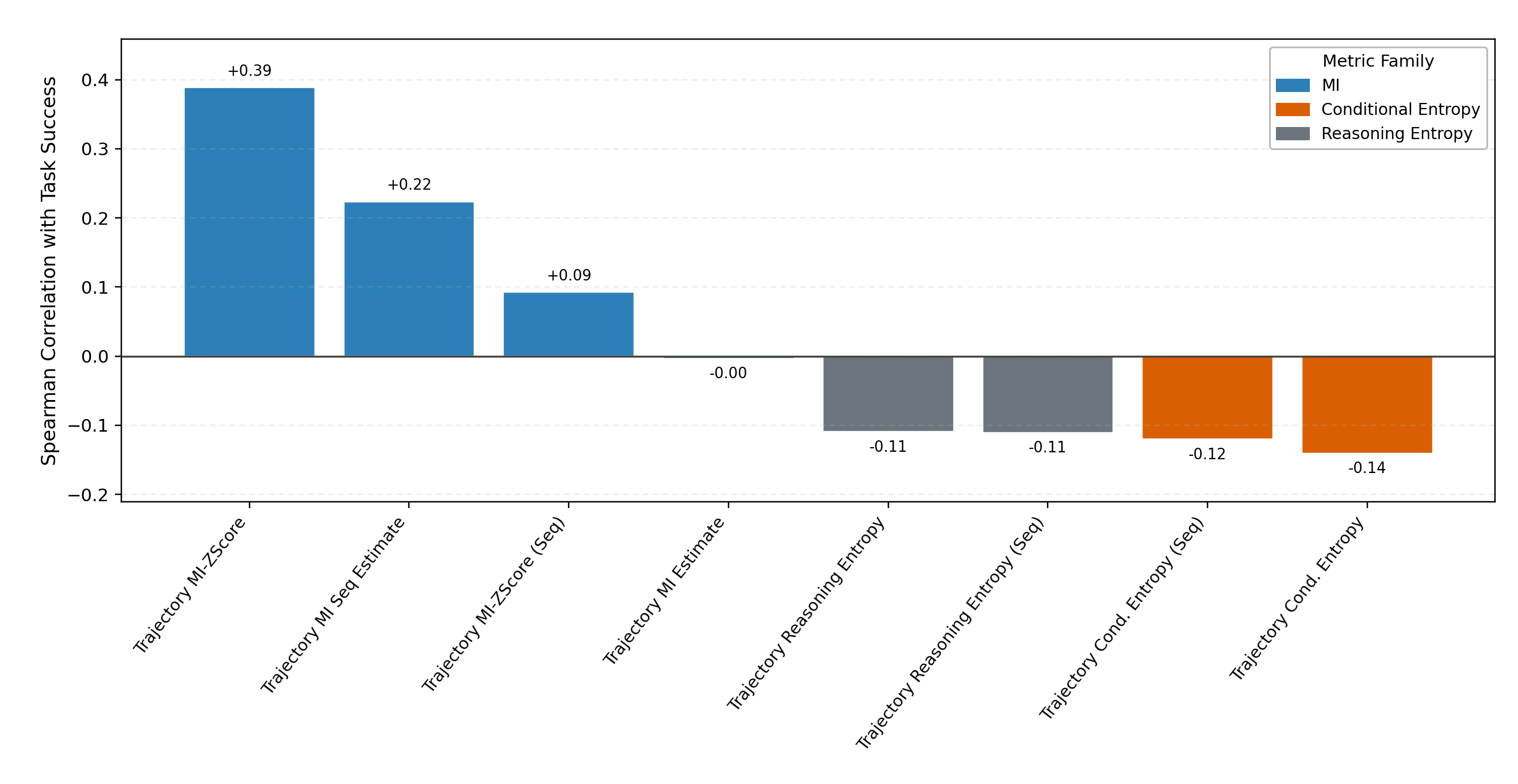
MI-family metrics (blue) achieve positive correlations with task success (+0.39), while entropy metrics show near-zero or negative correlations (−0.11 to −0.14) — confirming entropy is directionally misleading.
Correlation table: RV vs candidate proxies
| Variable | Spearman ↑ | Pearson ↑ | |
|---|---|---|---|
| Reward | 0.630 | 0.650 | Strong positive |
| Retrieval Acc (our diagnostic) | 0.130 | 0.150 | Weak positive |
| Response Length | 0.120 | 0.080 | Weak positive |
| MI (traj, est) | -0.100 | -0.170 | Negative |
| Conditional Entropy | -0.140 | -0.180 | Negative — misleading |
Format validity cannot detect collapse either
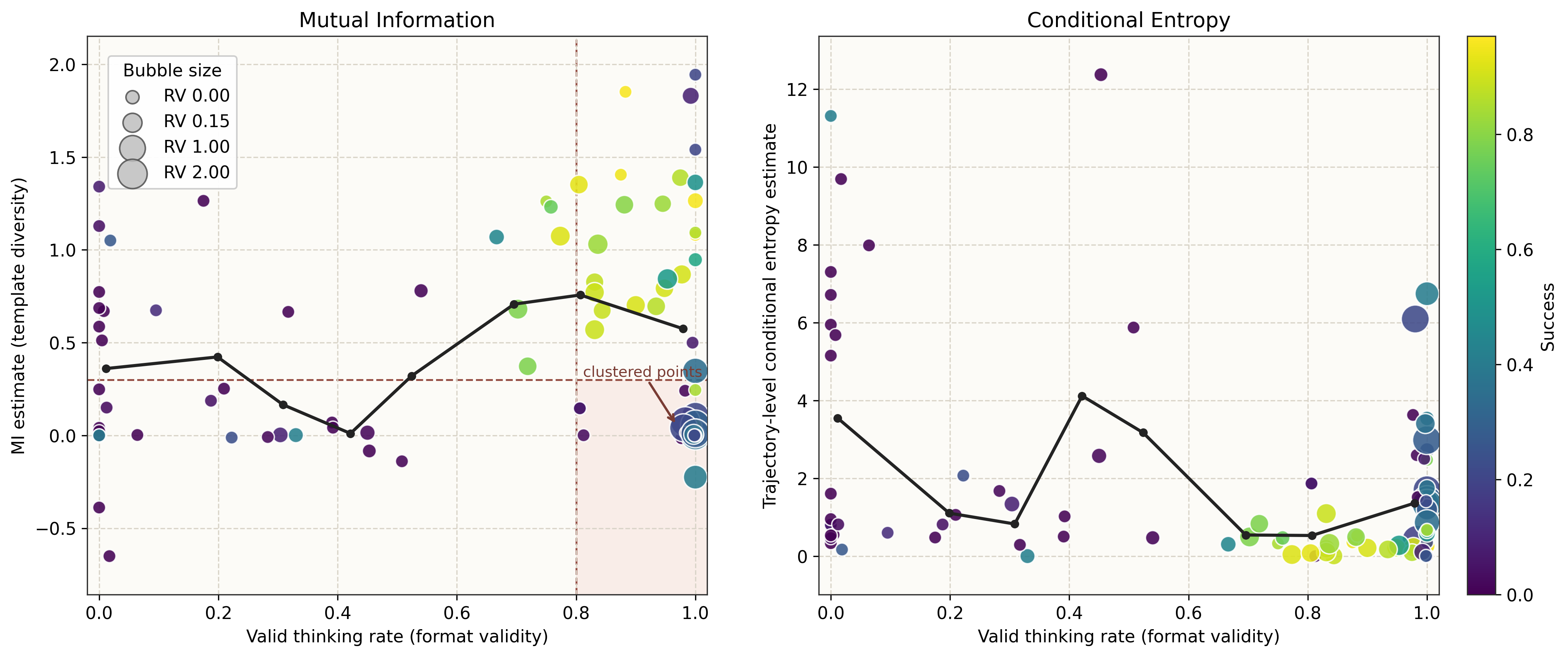
Runs can remain highly valid while exhibiting low MI. Validity-based metrics alone are not sufficient to detect collapse — content-sensitive measures are needed.
Gradient decomposition by reward-variance buckets
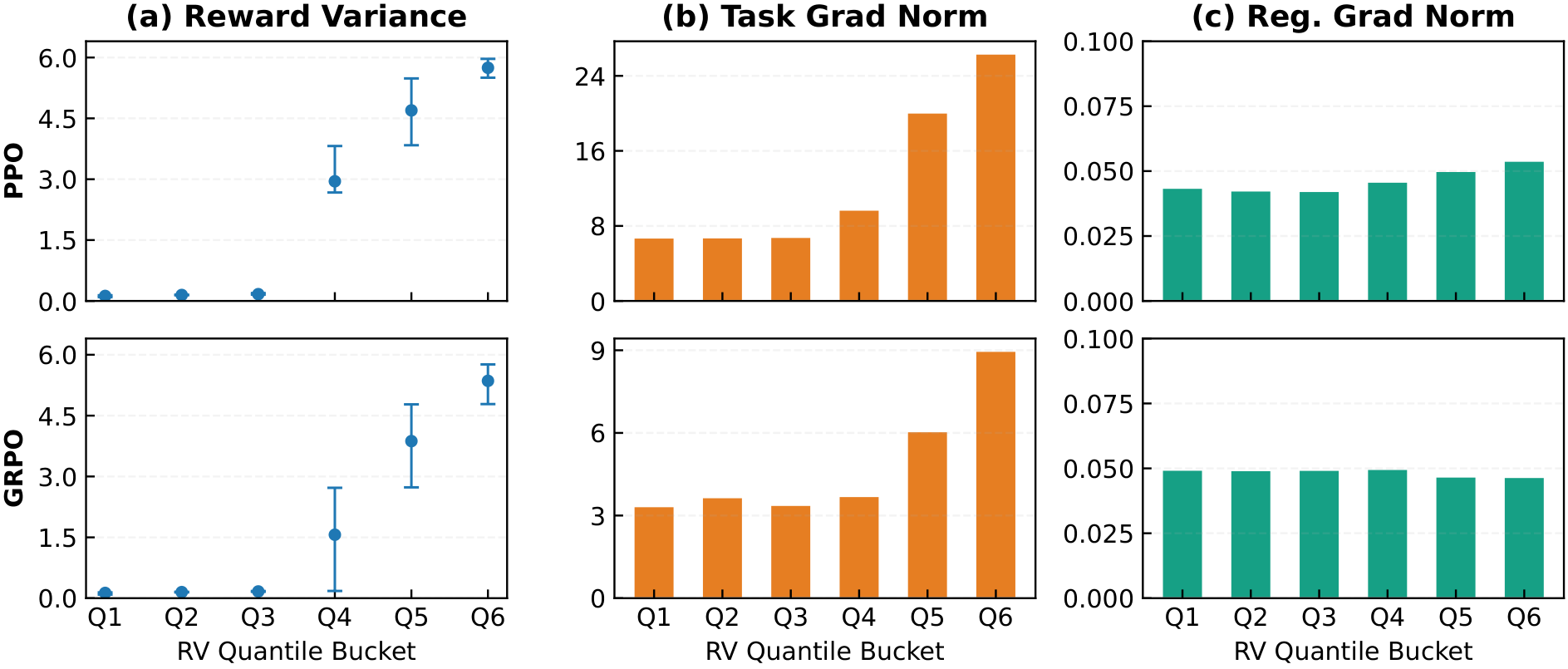
Extended gradient decomposition at step 101
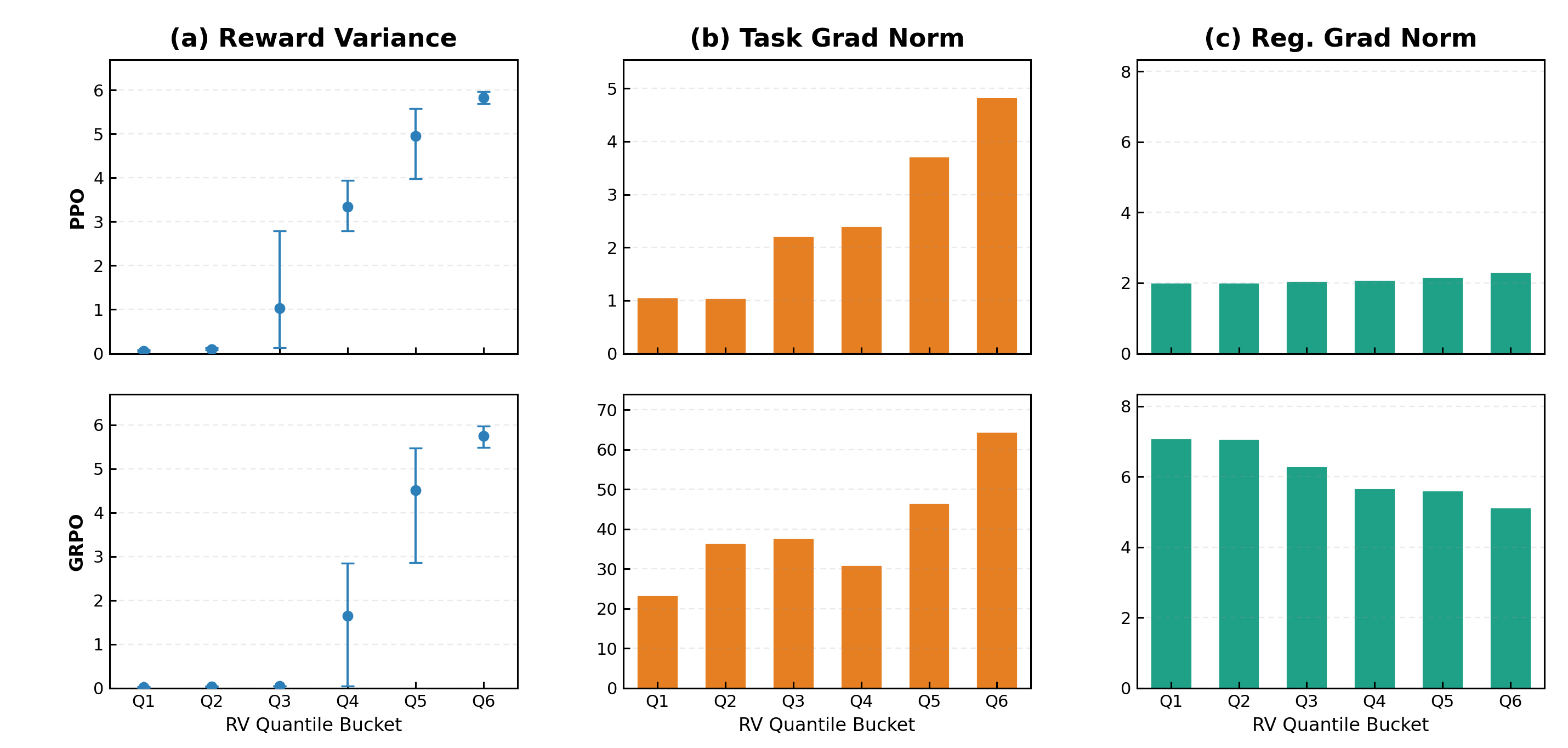
Complementary gradient analysis at training step 101 under both PPO (top) and GRPO (bottom). The same three trends hold: RV increases Q1→Q6, task gradient scales with RV, and regularization gradient stays flat.
Reward variance decreases over training
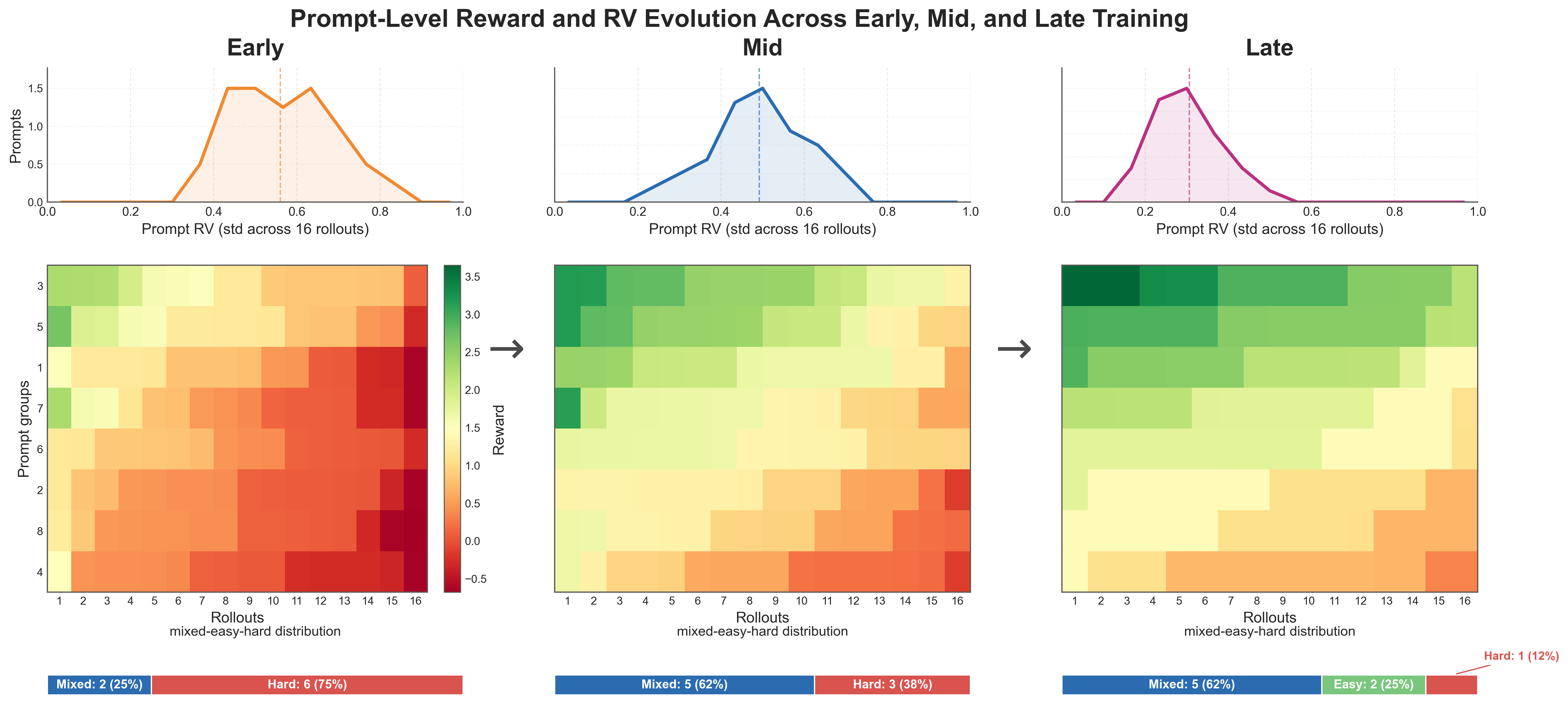
From early to late training, the hard-prompt subset contracts while mixed prompts expand, and prompt-level RV shifts downward — rollout rewards become progressively more uniform, directly driving template collapse.
Adaptive filtering responds to SNR dynamics
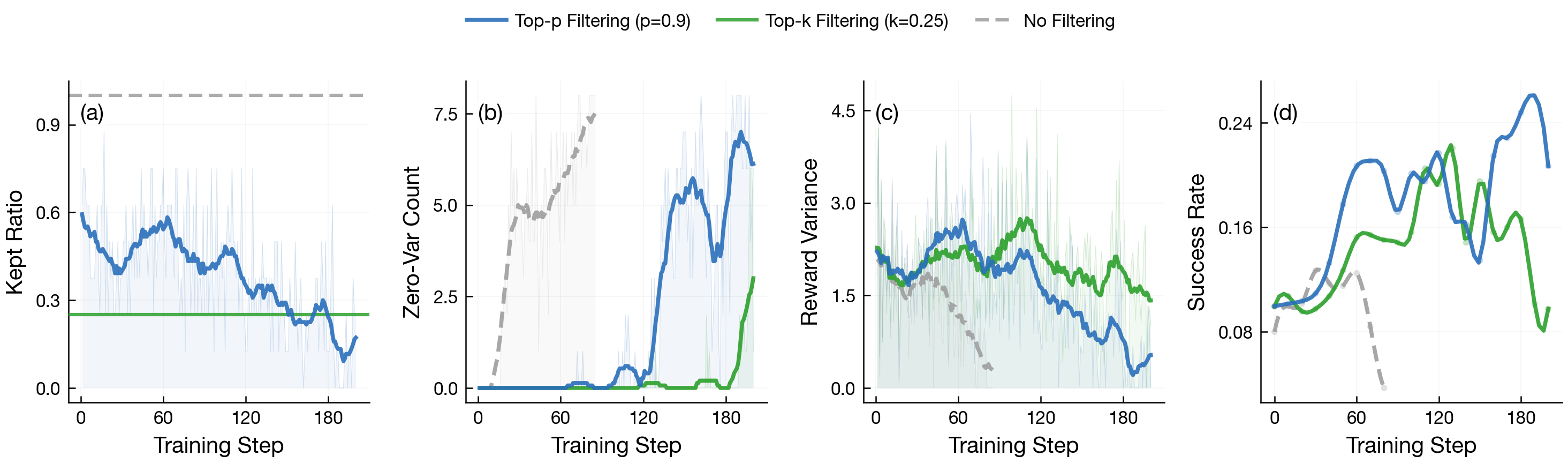
The kept ratio decreases as training progresses and more prompts yield near-zero reward variance. RV-aware filtering is adaptive: it applies stronger selection pressure precisely when task-discriminative signal is weakest.
Filtering across diverse environments
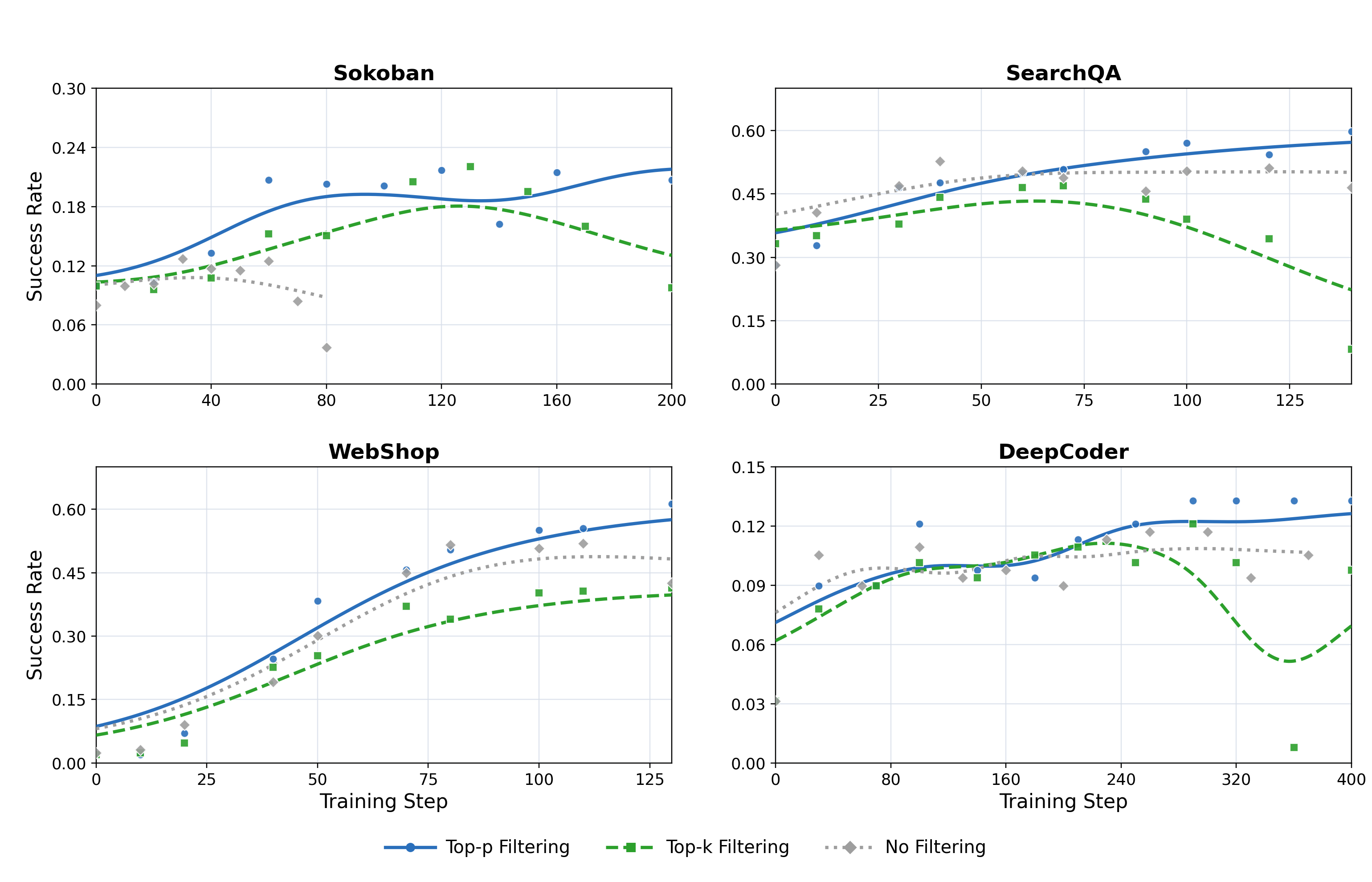
Top-p Filtering (orange) consistently outperforms both Top-k Filtering (blue) and No Filtering (gray) across Sokoban, SearchQA, WebShop, and DeepCoder — adaptive proportional selection is more effective than fixed-count filtering.
Comprehensive results matrix
| Experiment Variant | Sokoban | FrozenLake | MetaMathQA | Countdown | Average Δ |
|---|---|---|---|---|---|
| Baseline Algorithm | |||||
| PPO · Qwen2.5-3B | 12.9 (+16.0) | 67.0 (+10.9) | 92.6 (+0.6) | 97.9 (+0.0) | +6.9 |
| RL Algorithm (Qwen2.5-3B) | |||||
| DAPO | 16.2 (+5.1) | 66.8 (+2.1) | 90.8 (+2.8) | 95.7 (+1.6) | +2.9 |
| GRPO | 12.1 (+9.0) | 70.9 (+2.3) | 91.2 (+1.2) | 95.7 (+2.2) | +3.7 |
| Dr. GRPO | 12.1 (-0.4) | 23.2 (+0.6) | 91.2 (+1.4) | 96.5 (+1.4) | +0.8 |
| Model Scale (PPO) | |||||
| Qwen2.5-0.5B | 3.3 (+22.9) | 19.5 (+0.0) | 10.0 (-0.2) | 23.0 (-0.7) | +5.5 |
| Qwen2.5-1.5B | 17.0 (+6.2) | 36.5 (+1.6) | 80.3 (+7.0) | 56.6 (+1.6) | +4.1 |
| Qwen2.5-7B | 42.4 (+4.9) | 85.0 (-0.6) | 84.0 (+11.7) | 97.7 (+0.3) | +4.1 |
| Model Type (PPO) | |||||
| Qwen2.5-3B-Instruct | 22.5 (+14.2) | 83.6 (+2.3) | 91.2 (+0.4) | 96.3 (-0.6) | +4.1 |
| Llama3.2-3B | 24.4 (+18.8) | 84.6 (-0.2) | 86.1 (+3.7) | 99.2 (-1.2) | +5.3 |
| Modality — Qwen2.5-VL-3B (PPO) | |||||
| Text input | 53.0 (+6.0) | 16.0 (+53.5) | — | — | +29.8 |
| Image input | 65.0 (+12.0) | 19.5 (+59.5) | — | — | +35.8 |
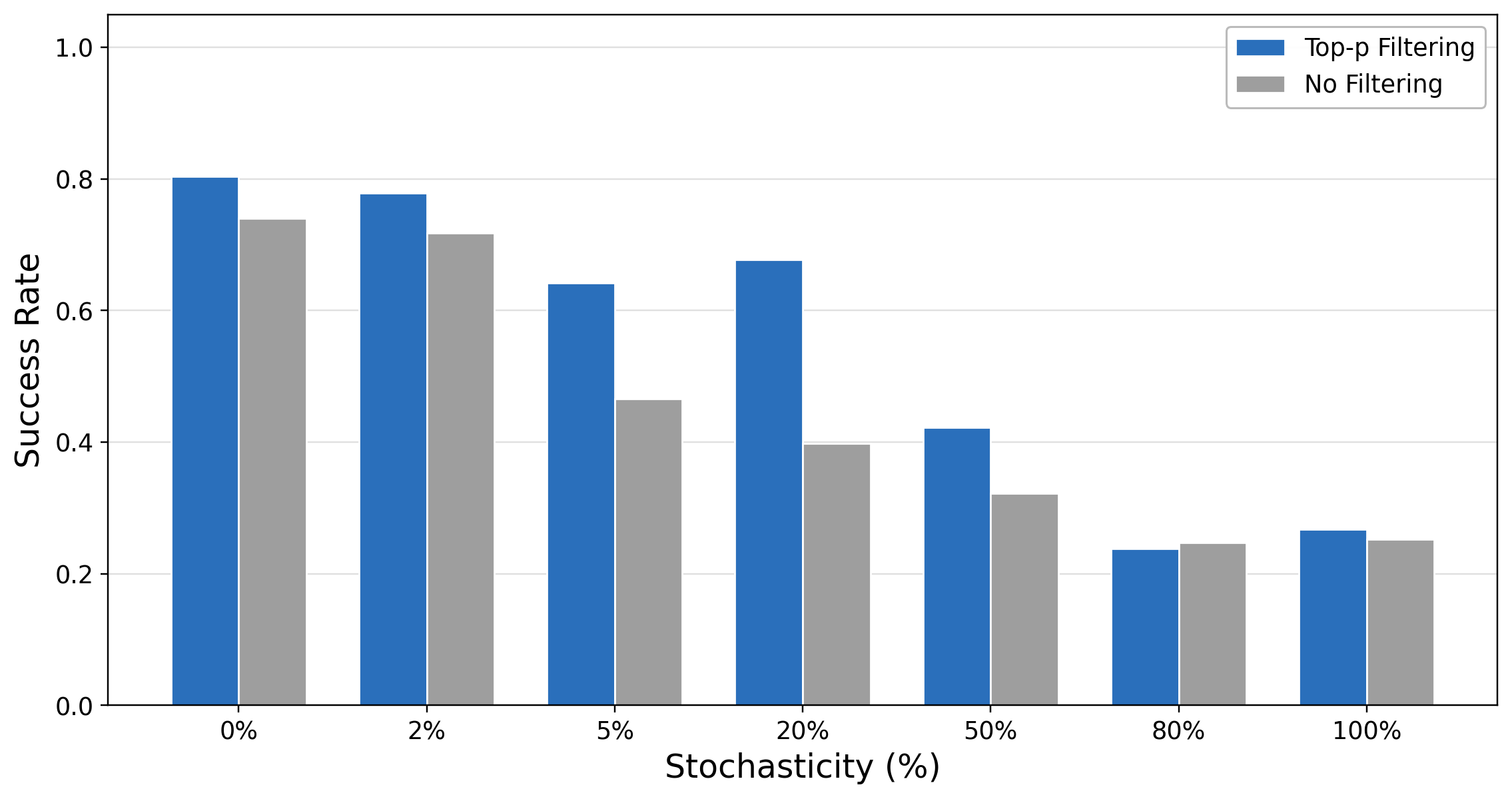
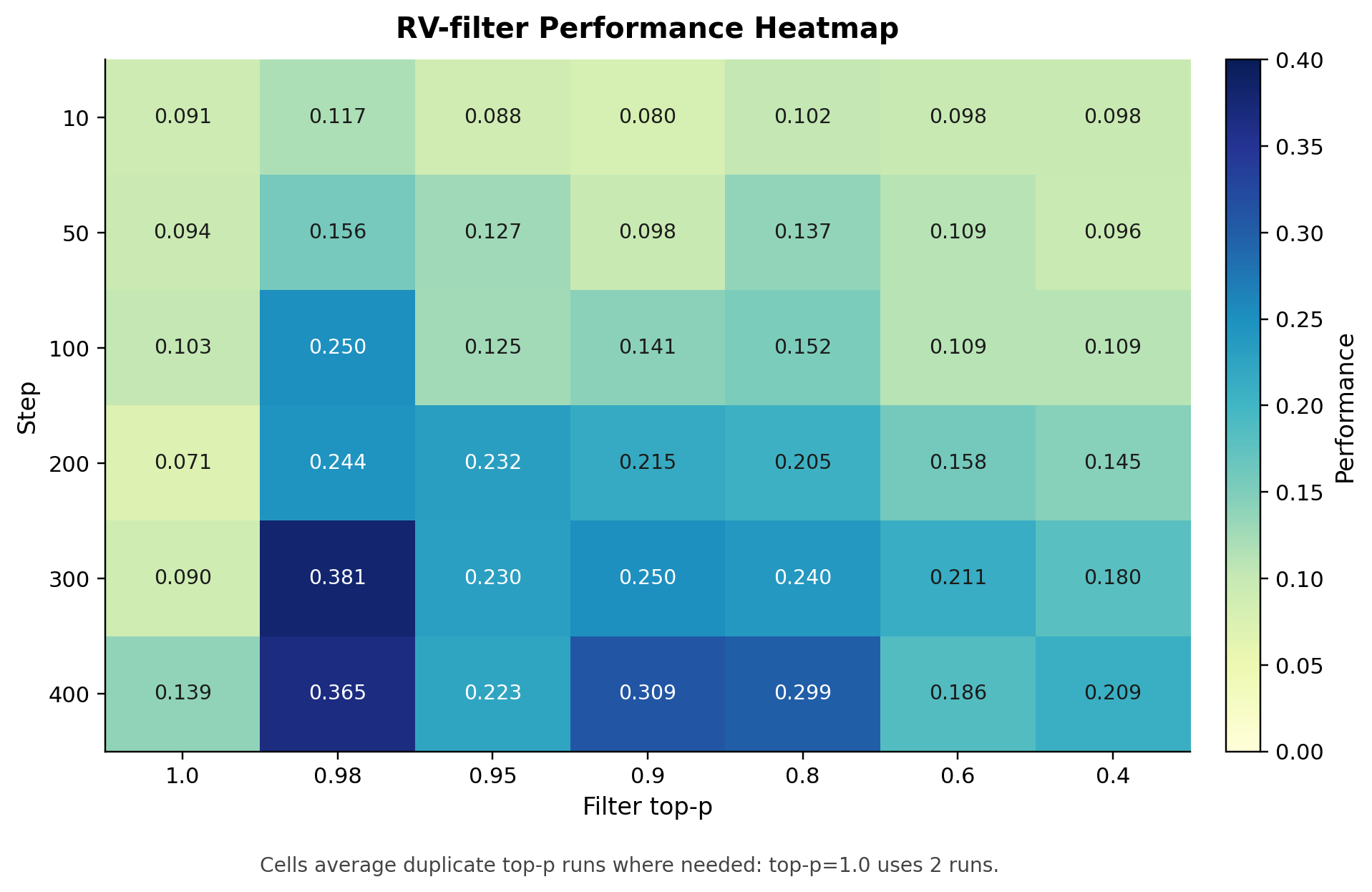
Each cell reports validation success rate at the corresponding checkpoint. Moderate filtering (top-p ∈ [0.8, 0.98]) consistently achieves the highest performance. Overly aggressive filtering (top-p ≤ 0.6) or no filtering (top-p = 1.0) yields lower returns.
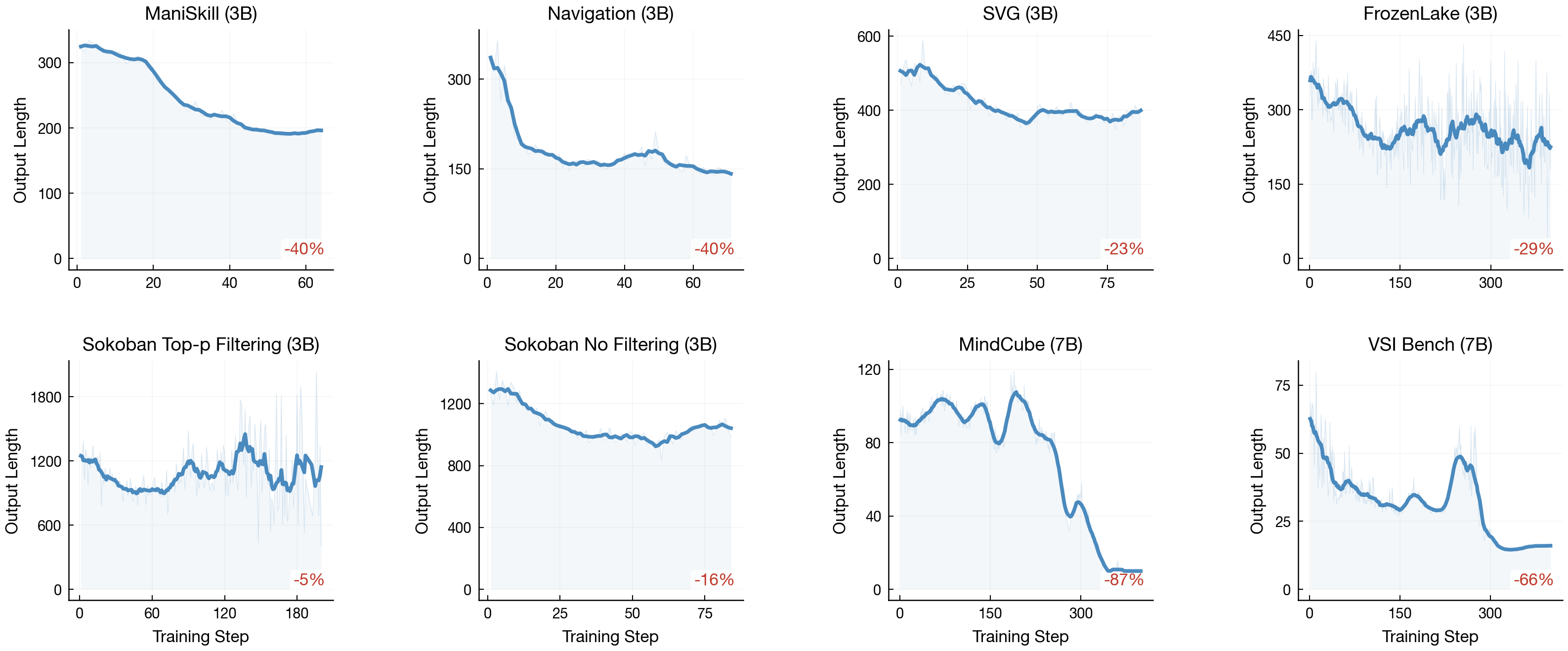
Output token count over training steps across eight environments. All environments exhibit consistent decline (−5% to −66%), across model sizes (3B and 7B) and both with and without RV filtering.
Citation
If you find this work useful, please cite:
@misc{wang2026ragen2reasoningcollapseagentic,
title={RAGEN-2: Reasoning Collapse in Agentic RL},
author={Zenus Wang and Chi Gui and Xing Jin and Qineng Wang and Licheng Liu and Kangrui Wang and Shiqi Chen and Linjie Li and Zhengyuan Yang and Pingyue Zhang and Yiping Lu and Jiajun Wu and Li Fei-Fei and Lijuan Wang and Yejin Choi and Manling Li},
year={2026},
eprint={2604.06268},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2604.06268},
}