BAGEN
Are LLM Agents Budget-Aware?
Agents are deployed with resource constraints: token, money, and time budgets. We ask: do they know how much budget they will spend?
We formalize budget awareness as progressive interval estimation: mid-execution, can the agent provide a calibrated interval on remaining budget and detect when a task is no longer finishable?
Method
Two Budget Modalities
The compute the model generates, primarily token consumption across reasoning steps. Tested on Sokoban, Search-R1, and SWE-bench.
The cost the agent commits in the environment: money, time, and warehouse capacity. Multi-dimensional, coupled constraints. Tested on our Warehouse environment.
Progressive Interval Estimation + Rollout-Replay
At every turn k, the estimator returns either a budget interval or an impossible declaration:
impossible if completion no longer achievable This separates estimation ability from task completion, since estimation itself would consume tokens if done inline.
Three Sub-Capability Metrics
Can the agent tell whether the task will succeed? Scored as Macro-F₁ over feasible / impossible classes, at first turn and all turns.
For tasks that ultimately fail, does the agent raise the alarm early? Scored as Fail-F₁ on the impossible class only.
On successful trajectories, how accurate and tight is the predicted interval? Scored as coverage × tightness, plus midpoint relative error.
4 Environments × 5 Frontier Models
8×8 grid planning task, 2,500-token cap.
Multi-hop information retrieval, 3,500-token cap.
GitHub issue resolution, 160-turn cap.
Supply-chain from real enterprise data. 3 coupled budgets: cost (USD), time (weeks), occupancy (item-weeks).
Key Findings
Click each finding to expand the evidence.
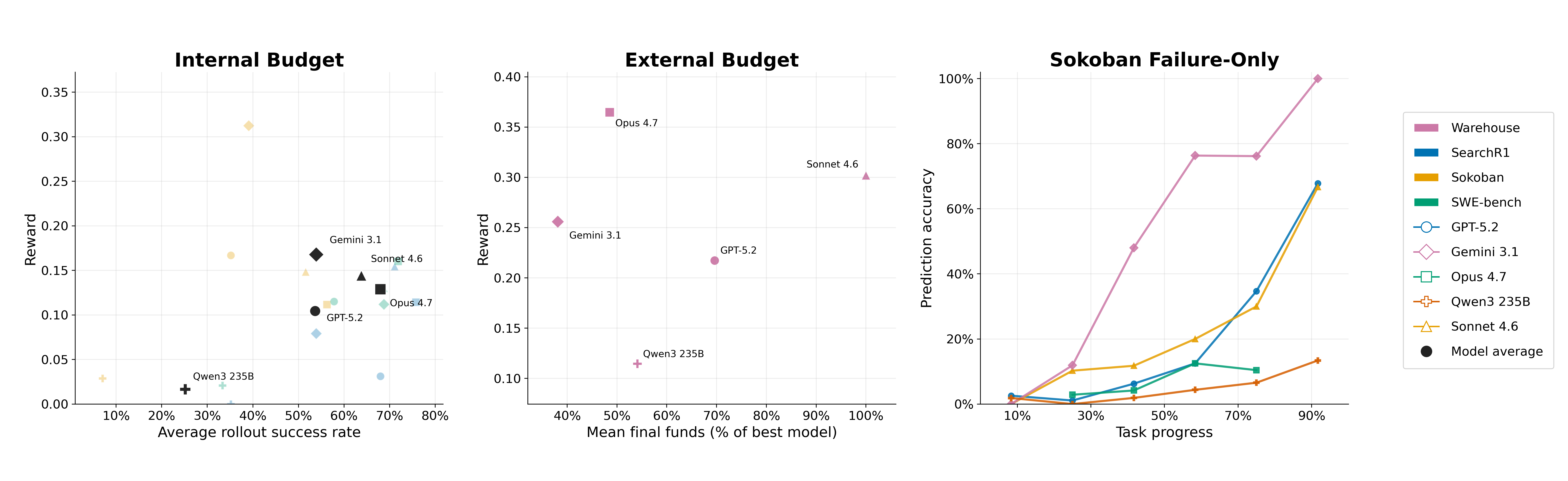
Left & middle: task success rate correlates only weakly with budget estimation quality for both internal and external budgets. Right: on failed Sokoban trajectories, estimation accuracy improves as more progress is observed, but the largest gains appear only very late.
Full Results Table
| Model | Success | F1@1 | F1@All | Fail-F1 | Hit Rate | Reward |
|---|---|---|---|---|---|---|
| SWE-bench | ||||||
| Claude Opus 4.7 | 71.9% | 41.1% | 51.1% | 48.8% | 30.3% | 0.160 |
| Claude Sonnet 4.6 | 68.8% | 32.2% | 37.7% | 23.4% | 22.3% | 0.130 |
| Gemini 3.1 Pro | 68.8% | 39.2% | 58.2% | 52.0% | 23.2% | 0.112 |
| GPT-5.2 Instant | 57.8% | 43.5% | 40.2% | 21.2% | 44.3% | 0.115 |
| Qwen3-235B | 33.3% | 47.6% | 35.1% | 32.8% | 6.5% | 0.021 |
| Search-R1 | ||||||
| Claude Opus 4.7 | 75.8% | 39.4% | 40.5% | 5.6% | 23.1% | 0.114 |
| Claude Sonnet 4.6 | 71.1% | 37.9% | 33.3% | 0.0% | 36.5% | 0.154 |
| GPT-5.2 Instant | 68.0% | 40.2% | 38.3% | 0.0% | 21.4% | 0.031 |
| Gemini 3.1 Pro | 53.9% | 24.5% | 24.8% | 0.0% | 20.7% | 0.079 |
| Qwen3-235B | 35.2% | 33.2% | 23.9% | 30.9% | 0.0% | 0.000 |
| Sokoban | ||||||
| Claude Opus 4.7 | 56.2% | 46.3% | 45.6% | 16.0% | 46.4% | 0.112 |
| Claude Sonnet 4.6 | 51.6% | 46.4% | 53.6% | 33.9% | 45.1% | 0.148 |
| Gemini 3.1 Pro | 39.1% | 40.0% | 61.9% | 79.9% | 8.8% | 0.313 |
| GPT-5.2 Instant | 35.2% | 27.7% | 40.6% | 32.8% | 36.0% | 0.167 |
| Qwen3-235B | 7.0% | 6.3% | 12.6% | 20.4% | 10.8% | 0.029 |
| Warehouse (external budget) | ||||||
| GPT-5.2 Instant | — | 35.0% | 63.4% | 56.9% | 24.7% | 0.577 |
| Claude Opus 4.7 | — | 33.3% | 63.2% | 55.7% | 35.9% | 0.690 |
| Claude Sonnet 4.6 | — | 33.3% | 64.9% | 59.0% | 17.3% | 0.572 |
| Gemini 3.1 Pro | — | 42.0% | 67.0% | 62.8% | 50.2% | 0.698 |
| Qwen3-235B | — | 41.0% | 60.8% | 56.0% | 17.3% | 0.483 |
Cumulative optimism across models
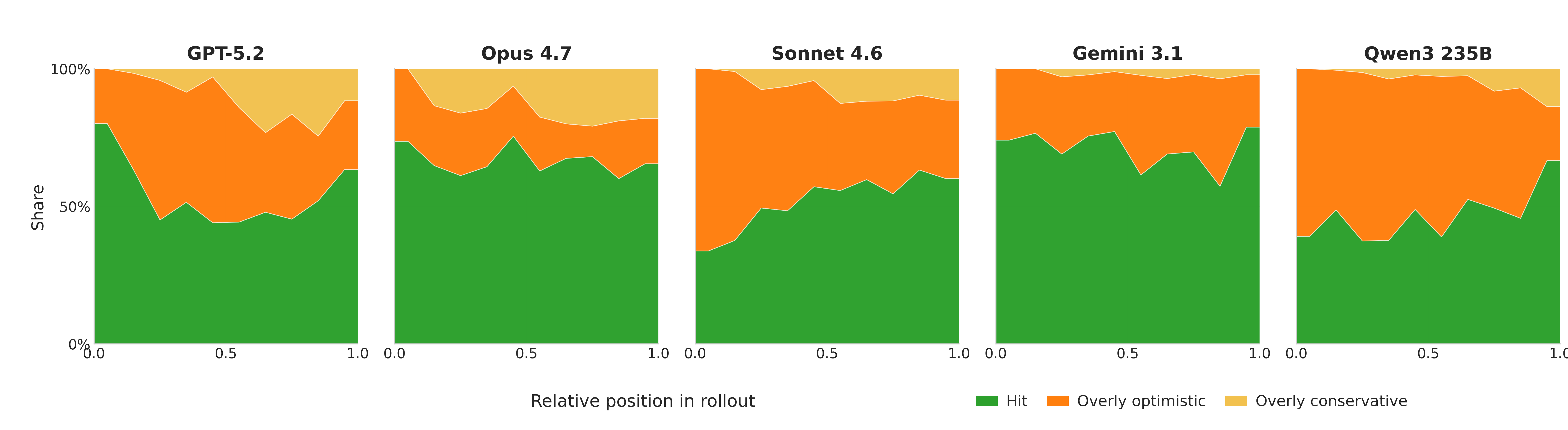
Models generally estimate budget too optimistically throughout the rollout. Conservative bias increases with rollout progress, but remains secondary to optimism overall.
First-turn vs. all-turn feasibility F₁
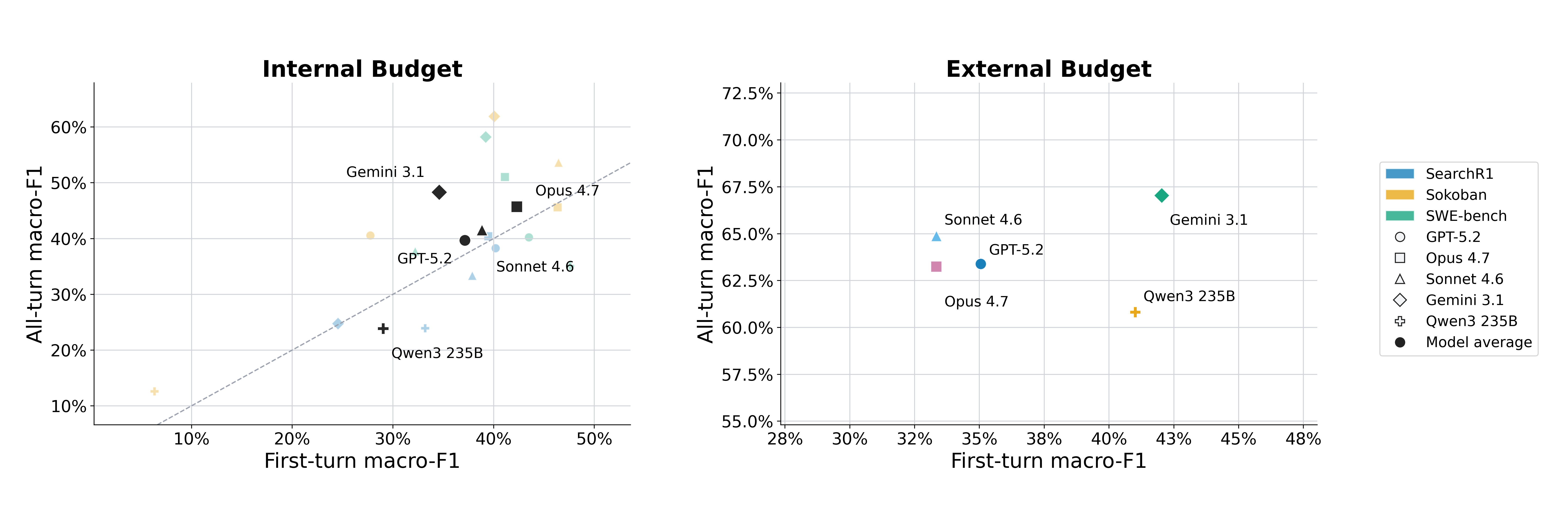
Points scatter on both sides of the equality line: first-turn predictions do not reliably summarize what the same agent would say after seeing partial progress. On Sokoban, Gemini improves by +21.9 F₁ points; on Search-R1, Qwen3-235B drops 9.3 points.

Failure is recognized late: across environments, models often label failed trajectories as impossible only after much of the token budget has already been spent.
Early Stopping Policy Results
A simple policy: terminate whenever the model predicts impossible. False aborts stop a would-have-succeeded trajectory; false continues miss a chance to save compute.
| Model | False-Abort Rate | Tokens Saved | Stopped Failed Rollouts |
|---|---|---|---|
| GPT-5.2 Instant | 6.6% | 64.1% | 124 / 215 |
| Claude Opus 4.7 | 2.2% | 28.2% | 62 / 169 |
| Claude Sonnet 4.6 | 3.3% | 49.6% | 101 / 183 |
| Gemini 3.1 Pro | 2.8% | 55.7% | 123 / 221 |
| Qwen3-235B | 4.9% | 38.8% | 140 / 306 |
SFT + RL training on Sokoban
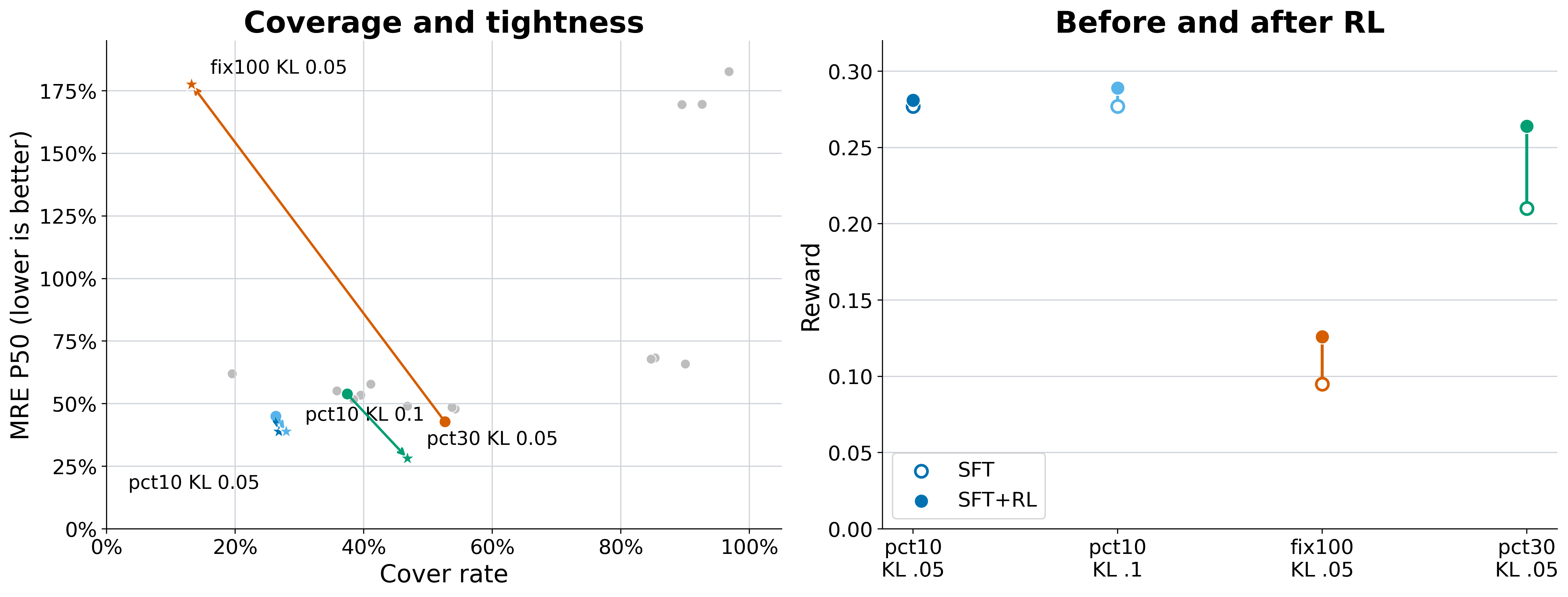
Left: coverage vs. midpoint error for SFT checkpoints and their SFT+RL continuations. Right: reward before and after RL from the same SFT starts. RL improves estimation only when starting from a suitable SFT initialization; RL alone collapses.
SFT interval-width ablation
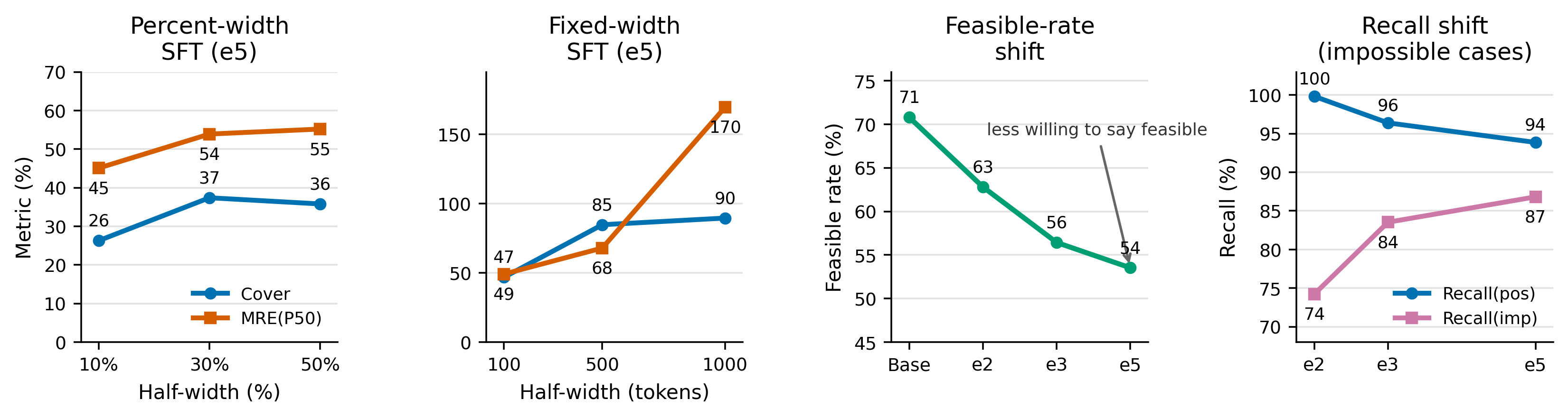
SFT choices control the estimator's behavior. Wider interval targets improve coverage but increase midpoint error. Longer SFT makes the model more conservative by reducing feasible predictions and improving recall on impossible cases.
impossible or emits invalid formats; RL cannot recover capability from sparse reward on its own.Citation
If you find this work useful, please cite:
@misc{bagen2026,
title={BAGEN: Are LLM Agents Budget-Aware?},
author={Yuxiang Lin and Zihan Wang and Mengyang Liu and Yuxuan Shan and Longju Bai and Junyao Zhang and Xing Jin and Boshan Chen and Jinyan Su and Xingyao Wang and Jiaxin Pei and Manling Li},
year={2026},
eprint={2606.00198},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2606.00198},
}